titanicで色々なアルゴリズムを試してみた
いくつかのアルゴリズムの精度検証のため、titanicデータセットを使ってモデルを構築します。
今回は以下のアルゴリズムを実装します。
前処理
import numpy as np import pandas as pd train_csv = './dataset/train.csv' df = pd.read_csv(train_csv) print(df.isnull().sum() / len(df))
結果
PassengerId 0.000000 Survived 0.000000 Pclass 0.000000 Name 0.000000 Sex 0.000000 Age 0.198653 SibSp 0.000000 Parch 0.000000 Ticket 0.000000 Fare 0.000000 Cabin 0.771044 Embarked 0.002245 dtype: float64
Ageは20%がNull、Cabinは77%がNull、そのほか、EmbarkedにNullが存在
- Ageは平均値で補完する。
- Cabinは77%と多く欠損しているため、今回予測には使用しない。
- Embarkedは欠損データ行を学習データから除外する。
#Ageの平均値補完 df['Age'] = df['Age'].fillna(df['Age'].mean()) #Cabinの除外 df = df.drop('Cabin', axis=1) #Embarkedがnullの行を除外 df = df[df['Embarked'].isna() == False]
文字列データとして、Name、Sex、Ticket、Embarkedが存在し、これを予測に使用する場合は数値データに変換する必要がある。
今回は、Name、Ticketは学習データから除外し、Sex,Embarkedはダミー変数化する。
また、予測に関係ないPassengerIDも除外する。(これが予測にプラスに働く場合もあるが、現実問題では解釈できないので意味あるの?という感じ)
これらの処理を行って、train_test_splitでtrain_data:test_data=8:2にデータセットを分割する。
stratifyで指定すると、データ全体のバランスを維持してtrain_dataとtest_dataに分割できる。
#不要列の除外 df = df.drop(['Name', 'Ticket', 'PassengerId'], axis=1) #ダミー変数化 df = pd.get_dummies(df,drop_first=True) #変数 from sklearn.model_selection import train_test_split df_x = df.drop('Survived', axis=1) df_y = df['Survived'] X_train, X_test, y_train, y_test = train_test_split( df_x, df_y, test_size=0.2, random_state=42, stratify=df_y)
モデリング
かなり長くなってしまったので、詳細は最後にまとめて掲載する。
モデリングで最も基本的な記述は以下である。これで学習が行われる。(例として、k-NNをfitさせている。)
from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=k) #kは任意の数値 knn.fit(X_train, y_train) score_train = knn.score(X_train, y_train) #train_dataでの精度算出 score_test = knn.score(X_test, y_test) #test_dataでの精度算出
この「knn」や「KNeighborsClassifier」の部分がアルゴリズムによって異なる。
結果
train_dataとtest_dataでの各アルゴリズムでの精度を以下に示す。

決定木系がtest_dataに対しても高い精度が出ている。 ハイパーパラメータ調整を行えば精度向上が見込める。
SVMでは、カーネル(RBF法)を使用する場合に、標準化によって精度が大きく向上している。
ちなみに、決定木系のアルゴリズムは、そのモデルでの変数重要度を視覚化することが可能。
fi = pd.DataFrame([xgb.feature_importances_],columns=X_train.columns, index=['FeatureImportance']).T fi = fi.sort_values(by='FeatureImportance', ascending=True) fi.plot(kind='barh' )
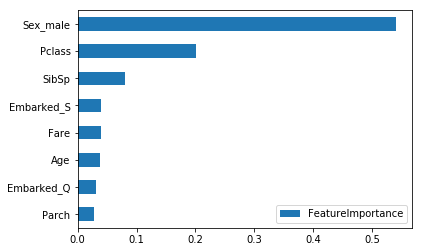
XGBoostでは性別が重要視されていることがわかる。
まとめ
精度を出したい場合は決定木系、SVMが安定、という感じがある。
(もちろんデータの特性によるだろうから、まずはデータの観察が重要)
ベースラインとして、k-NNを手始めに組んでみるのもありかな。
実装コード
k-NN
from sklearn.neighbors import KNeighborsClassifier list_k = [] list_train = [] list_test = [] for k in range(1,50): #kの値を1~50で試行 knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) score_train = knn.score(X_train, y_train) score_test = knn.score(X_test, y_test) list_k.append(k) list_train.append(score_train) list_test.append(score_test) # プロット plt.xlabel("k") plt.ylabel("score") plt.plot(list_k, list_train) plt.plot(list_k, list_test) print(list_test) a = max(list_test) b = list_k[list_test.index(a)] c = list_train[list_test.index(a)] print("検証用データセットの最高精度: {}".format(a)) print("kの値: {}".format(b)) print("k: {} の学習用データセットの精度: {}".format(b,c))
ロジスティック回帰
from sklearn.linear_model import LogisticRegression list_c = [] list_train = [] list_test = [] for c in [10 ** i for i in range(-5, 5)]: #ハイパーパラメータCの調整 lr = LogisticRegression(C=c, random_state=42) lr.fit(X_train, y_train) score_train = lr.score(X_train, y_train) score_test = lr.score(X_test, y_test) list_c.append(c) list_train.append(score_train) list_test.append(score_test) print(list_c) print(list_test) a = max(list_test) b = list_c[list_test.index(a)] t = list_train[list_test.index(a)] print("検証用データセットの最高精度: {}".format(a)) print("cの値: {}".format(b)) print("c: {} の学習用データセットの精度: {}".format(b,t))
from sklearn.svm import SVC list_c = [] list_train = [] list_test = [] for c in [10 ** i for i in range(-5, 5)]: svc = SVC(C=c, kernel='linear', random_state=42)#rbfの場合はkernel='rbf'とする svc.fit(X_train, y_train) score_train = svc.score(X_train, y_train) score_test = svc.score(X_test, y_test) list_c.append(c) list_train.append(score_train) list_test.append(score_test) print(list_c) print(list_test) a = max(list_test) b = list_c[list_test.index(a)] t = list_train[list_test.index(a)] print("検証用データセットの最高精度: {}".format(a)) print("cの値: {}".format(b)) print("c: {} の学習用データセットの精度: {}".format(b,t))
標準化する場合はStandardScalerで行う
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(X_train) X_train_std = pd.DataFrame(scaler.transform(X_train), columns=X_train.columns) X_test_std = pd.DataFrame(scaler.transform(X_test), columns=X_test.columns)
ナイーブベイズ
# 0,1の問題なので、ベルヌーイ分布を仮定する # ハイパーパラメータとしてalphaが存在するが、精度は大きく変動しないため、調整は行わない from sklearn.naive_bayes import BernoulliNB bnb = BernoulliNB() bnb.fit(X_train, y_train) score_train = bnb.score(X_train, y_train) score_test = bnb.score(X_test, y_test) print("学習用データセットの精度: {}".format(score_train)) print("検証用データセットの精度: {}".format(score_test))
決定木
# 決定木はハイパーパラメータが多いため、今回はひとまずデフォルトで構築する from sklearn.tree import DecisionTreeClassifier dtc = DecisionTreeClassifier() dtc = dtc.fit(X_train, y_train) score_train = dtc.score(X_train, y_train) score_test = dtc.score(X_test, y_test) print("学習用データセットの精度: {}".format(score_train)) print("検証用データセットの精度: {}".format(score_test))
ランダムフォレスト
# 決定木はハイパーパラメータが多いため、今回はひとまずデフォルトで構築する from sklearn.ensemble import RandomForestClassifier rndf = RandomForestClassifier(random_state=42) rndf = rndf.fit(X_train, y_train) score_train = rndf.score(X_train, y_train) score_test = rndf.score(X_test, y_test)
XGBoost
# 決定木はハイパーパラメータが多いため、今回はひとまずデフォルトで構築する from xgboost import XGBClassifier xgb = XGBClassifier(random_state=42) xgb.fit(X_train, y_train) score_train = xgb.score(X_train, y_train) score_test = xgb.score(X_test, y_test) print("学習用データセットの精度: {}".format(score_train)) print("検証用データセットの精度: {}".format(score_test))
LightGBM
# 決定木はハイパーパラメータが多いため、今回はひとまずデフォルトで構築する from lightgbm import LGBMClassifier lgb = LGBMClassifier(random_state=42) lgb.fit(X_train, y_train) score_train = lgb.score(X_train, y_train) score_test = lgb.score(X_test, y_test) print("学習用データセットの精度: {}".format(score_train)) print("検証用データセットの精度: {}".format(score_test))