Pythonではじめる機械学習ー2章まとめ
長らく更新が空いてしまいました。
読んだ本を忘れないように、章ごとにまとめていきます。
今回はPythonではじめる機械学習の2章(教師あり学習)です。
もっと細かい部分を見たい場合は書籍を見てください。

Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
- 作者:Andreas C. Muller,Sarah Guido
- 発売日: 2017/05/25
- メディア: 単行本(ソフトカバー)
概要
教師あり学習
- 学習用データとして、入力データと出力データのセットを用いる
- クラス分類(classification)と、回帰(regression)に大別される
- クラス分類
あらかじめ定められた選択肢の中からクラスラベルを予測する(ex.スパムメールの判別) - 回帰
連続値を予測する(ex.年収の予測)
- クラス分類
モデルの複雑さ
教師あり機械学習アルゴリズム
- k-最近傍法(k-NN)
- 予測したいデータに近い
個の学習用データポイントを参考に多数決で出力を決める
- 予測したいデータに近い
- 線形回帰
で表される線形関数で予測を行う
- 高次元のデータセットに適する
- リッジ回帰
- Lasso
- ロジスティック回帰
- シグモイド関数(
)をベースに予測モデルを作成
で表される
- 2値分類に利用される
- シグモイド関数(
- SVM
- ナイーブベイズクラス分類器
- 決定木
- 非常に高速で、データのスケールを考慮する必要が無い。
- 可視化が可能で説明しやすい
- 決定木を拡張させたものに以下がある。
- ランダムフォレスト
- ほとんどの単一の決定木よりも高速で、頑健で、強力
- データのスケールを考慮する必要が無いが、高次元の疎なデータには不適
- XGBoost
- ランダムフォレストよりも時間がかかるが、予測は早く、メモリ使用量も小さい
- パラメータに敏感だが、強力で、Kaggleでもよく使用される
- LightGBM
- XGBoostと同じ勾配ブースティングの一種。XGBoostよりも計算時間が短い傾向がある
- 決定木の構造が複雑になりやすく、過学習しやすい
- ニューラルネットワーク
- 非常に複雑なモデルを構築できる
- 大規模データセットに有効
- データのスケールを調整する必要があり、パラメータに敏感
後々、各アルゴリズムの詳細説明記事を書いていこうと思う。
精度比較(分類)
titanicデータセットでいくつかのアルゴリズムの精度を比較した。
実装の詳細はこちらを参照。
brskun.hatenablog.com
以下に各アルゴリズムの精度結果を示す。

titanicで色々なアルゴリズムを試してみた
いくつかのアルゴリズムの精度検証のため、titanicデータセットを使ってモデルを構築します。
今回は以下のアルゴリズムを実装します。
前処理
import numpy as np import pandas as pd train_csv = './dataset/train.csv' df = pd.read_csv(train_csv) print(df.isnull().sum() / len(df))
結果
PassengerId 0.000000 Survived 0.000000 Pclass 0.000000 Name 0.000000 Sex 0.000000 Age 0.198653 SibSp 0.000000 Parch 0.000000 Ticket 0.000000 Fare 0.000000 Cabin 0.771044 Embarked 0.002245 dtype: float64
Ageは20%がNull、Cabinは77%がNull、そのほか、EmbarkedにNullが存在
- Ageは平均値で補完する。
- Cabinは77%と多く欠損しているため、今回予測には使用しない。
- Embarkedは欠損データ行を学習データから除外する。
#Ageの平均値補完 df['Age'] = df['Age'].fillna(df['Age'].mean()) #Cabinの除外 df = df.drop('Cabin', axis=1) #Embarkedがnullの行を除外 df = df[df['Embarked'].isna() == False]
文字列データとして、Name、Sex、Ticket、Embarkedが存在し、これを予測に使用する場合は数値データに変換する必要がある。
今回は、Name、Ticketは学習データから除外し、Sex,Embarkedはダミー変数化する。
また、予測に関係ないPassengerIDも除外する。(これが予測にプラスに働く場合もあるが、現実問題では解釈できないので意味あるの?という感じ)
これらの処理を行って、train_test_splitでtrain_data:test_data=8:2にデータセットを分割する。
stratifyで指定すると、データ全体のバランスを維持してtrain_dataとtest_dataに分割できる。
#不要列の除外 df = df.drop(['Name', 'Ticket', 'PassengerId'], axis=1) #ダミー変数化 df = pd.get_dummies(df,drop_first=True) #変数 from sklearn.model_selection import train_test_split df_x = df.drop('Survived', axis=1) df_y = df['Survived'] X_train, X_test, y_train, y_test = train_test_split( df_x, df_y, test_size=0.2, random_state=42, stratify=df_y)
モデリング
かなり長くなってしまったので、詳細は最後にまとめて掲載する。
モデリングで最も基本的な記述は以下である。これで学習が行われる。(例として、k-NNをfitさせている。)
from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=k) #kは任意の数値 knn.fit(X_train, y_train) score_train = knn.score(X_train, y_train) #train_dataでの精度算出 score_test = knn.score(X_test, y_test) #test_dataでの精度算出
この「knn」や「KNeighborsClassifier」の部分がアルゴリズムによって異なる。
結果
train_dataとtest_dataでの各アルゴリズムでの精度を以下に示す。
決定木系がtest_dataに対しても高い精度が出ている。 ハイパーパラメータ調整を行えば精度向上が見込める。
SVMでは、カーネル(RBF法)を使用する場合に、標準化によって精度が大きく向上している。
ちなみに、決定木系のアルゴリズムは、そのモデルでの変数重要度を視覚化することが可能。
fi = pd.DataFrame([xgb.feature_importances_],columns=X_train.columns, index=['FeatureImportance']).T fi = fi.sort_values(by='FeatureImportance', ascending=True) fi.plot(kind='barh' )
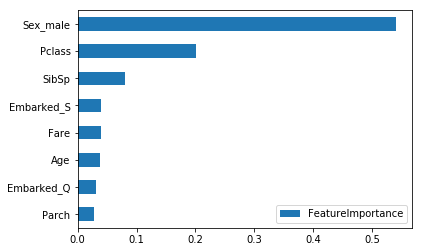
XGBoostでは性別が重要視されていることがわかる。
まとめ
精度を出したい場合は決定木系、SVMが安定、という感じがある。
(もちろんデータの特性によるだろうから、まずはデータの観察が重要)
ベースラインとして、k-NNを手始めに組んでみるのもありかな。
実装コード
k-NN
from sklearn.neighbors import KNeighborsClassifier list_k = [] list_train = [] list_test = [] for k in range(1,50): #kの値を1~50で試行 knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) score_train = knn.score(X_train, y_train) score_test = knn.score(X_test, y_test) list_k.append(k) list_train.append(score_train) list_test.append(score_test) # プロット plt.xlabel("k") plt.ylabel("score") plt.plot(list_k, list_train) plt.plot(list_k, list_test) print(list_test) a = max(list_test) b = list_k[list_test.index(a)] c = list_train[list_test.index(a)] print("検証用データセットの最高精度: {}".format(a)) print("kの値: {}".format(b)) print("k: {} の学習用データセットの精度: {}".format(b,c))
ロジスティック回帰
from sklearn.linear_model import LogisticRegression list_c = [] list_train = [] list_test = [] for c in [10 ** i for i in range(-5, 5)]: #ハイパーパラメータCの調整 lr = LogisticRegression(C=c, random_state=42) lr.fit(X_train, y_train) score_train = lr.score(X_train, y_train) score_test = lr.score(X_test, y_test) list_c.append(c) list_train.append(score_train) list_test.append(score_test) print(list_c) print(list_test) a = max(list_test) b = list_c[list_test.index(a)] t = list_train[list_test.index(a)] print("検証用データセットの最高精度: {}".format(a)) print("cの値: {}".format(b)) print("c: {} の学習用データセットの精度: {}".format(b,t))
from sklearn.svm import SVC list_c = [] list_train = [] list_test = [] for c in [10 ** i for i in range(-5, 5)]: svc = SVC(C=c, kernel='linear', random_state=42)#rbfの場合はkernel='rbf'とする svc.fit(X_train, y_train) score_train = svc.score(X_train, y_train) score_test = svc.score(X_test, y_test) list_c.append(c) list_train.append(score_train) list_test.append(score_test) print(list_c) print(list_test) a = max(list_test) b = list_c[list_test.index(a)] t = list_train[list_test.index(a)] print("検証用データセットの最高精度: {}".format(a)) print("cの値: {}".format(b)) print("c: {} の学習用データセットの精度: {}".format(b,t))
標準化する場合はStandardScalerで行う
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(X_train) X_train_std = pd.DataFrame(scaler.transform(X_train), columns=X_train.columns) X_test_std = pd.DataFrame(scaler.transform(X_test), columns=X_test.columns)
ナイーブベイズ
# 0,1の問題なので、ベルヌーイ分布を仮定する # ハイパーパラメータとしてalphaが存在するが、精度は大きく変動しないため、調整は行わない from sklearn.naive_bayes import BernoulliNB bnb = BernoulliNB() bnb.fit(X_train, y_train) score_train = bnb.score(X_train, y_train) score_test = bnb.score(X_test, y_test) print("学習用データセットの精度: {}".format(score_train)) print("検証用データセットの精度: {}".format(score_test))
決定木
# 決定木はハイパーパラメータが多いため、今回はひとまずデフォルトで構築する from sklearn.tree import DecisionTreeClassifier dtc = DecisionTreeClassifier() dtc = dtc.fit(X_train, y_train) score_train = dtc.score(X_train, y_train) score_test = dtc.score(X_test, y_test) print("学習用データセットの精度: {}".format(score_train)) print("検証用データセットの精度: {}".format(score_test))
ランダムフォレスト
# 決定木はハイパーパラメータが多いため、今回はひとまずデフォルトで構築する from sklearn.ensemble import RandomForestClassifier rndf = RandomForestClassifier(random_state=42) rndf = rndf.fit(X_train, y_train) score_train = rndf.score(X_train, y_train) score_test = rndf.score(X_test, y_test)
XGBoost
# 決定木はハイパーパラメータが多いため、今回はひとまずデフォルトで構築する from xgboost import XGBClassifier xgb = XGBClassifier(random_state=42) xgb.fit(X_train, y_train) score_train = xgb.score(X_train, y_train) score_test = xgb.score(X_test, y_test) print("学習用データセットの精度: {}".format(score_train)) print("検証用データセットの精度: {}".format(score_test))
LightGBM
# 決定木はハイパーパラメータが多いため、今回はひとまずデフォルトで構築する from lightgbm import LGBMClassifier lgb = LGBMClassifier(random_state=42) lgb.fit(X_train, y_train) score_train = lgb.score(X_train, y_train) score_test = lgb.score(X_test, y_test) print("学習用データセットの精度: {}".format(score_train)) print("検証用データセットの精度: {}".format(score_test))
時系列分析(ARIMAモデル実装)
ARIMAモデルの実装編です。
隼本を参考にしています。

時系列分析と状態空間モデルの基礎: RとStanで学ぶ理論と実装
- 作者:真哉, 馬場
- 発売日: 2018/02/14
- メディア: 単行本
前回の記事を前提に話を進めますので、まずはこちらを参照ください。
brskun.hatenablog.com
ARIMAモデル構築のステップ
前回の記事で、モデル構築のステップは以下のように進めると説明した。
- データを分析できる形に変換する
- ARIMAなどのモデルを適用し、次数を同定(=モデルの形を特定)する
- パラメータを推定する
- 推定されたモデルを評価する
- 予測する
この各ステップについて、Pythonで実装していく。
使用するデータはCOVID-19の日本における日次の新規感染者数のデータとする。
SIGNATEで開催中の下記コンペのデータを使用している。
(SIGNATE COVID-19 Case Dataset.xlsx)
signate.jp
==
COVID-19の感染者予測にこのモデルを適用することが適切かどうかは今回議論しない。
新規感染者数は検査数に依存し、その傾向をARIMAモデルでとらえることは難しいと考えられるが、私が時系列分析を学ぶきっかけになり、初めて時系列モデルを作ったデータであるため、このデータを使用する。
1.データを分析できる形に変換する
ARIMAモデルは定常過程に従うデータに適用することが前提となる。
定常性については前回記事を参照。
そのため、まずは分析したいデータが定常過程に従うかどうか、確認を行う。
データの確認
import pandas as pd df = pd.read_excel("SIGNATE COVID-19 Case Dataset.xlsx", sheet_name=1) df.head()
2020年1月16日~2020年8月8日までのデータが存在している。別途確認してほしいが、欠損値はない。(2020年8月8日現在)

この中から、新規感染者数の推移を確認する。
import matplotlib.pyplot as plt df_ts = pd.concat([df['日付'][1:], df['日本国内\n新規罹患者数'][1:]], axis=1) ts = df_ts.set_index('日付') fig = plt.figure(figsize=(12,8)) plt.plot(ts)

見た目の感想としては、期待値が一定でなく、任意のk地点間での共分散も一定でない(=定常性の定義からは外れる)ように見える。
定常性を持つかどうか、統計的な検定を行うことで確認する。
定常性の確認
定常性を確認する検定として、KPSS検定、ADF検定がある。
※隼本のP.64には、上の説明と同時に以下の定義もある。
- KPSS検定
モデルをと仮定するとき、
帰無仮説:
対立仮設:
- ADF検定
モデルをと仮定するとき、
帰無仮説:
対立仮設:
単位根過程とは、元データ(原系列)が非定常過程であり、原系列の差分を取ったデータ(差分系列)が定常過程となる過程のことである。
※差分系列:
つまり、KPSS検定で帰無仮説を棄却できれば、単位根過程がある(ランダムウォークが原系列を表すモデルに存在する)、と判断し、差分系列を取るべきだと判断する。
差分系列がKPSS検定で棄却できないとき、単位根過程があるとは言えない。(単位根過程が無い、とは断言できない。帰無仮説は採択できない。)
その場合に、ダメ押しでADF検定を行い、棄却できれば、そのデータに単位根過程が無い、と判断する。
・・・と私は隼本から解釈した。
KPSS検定とADF検定は以下で実行できる。
from scipy import stats import statsmodels.api as sm #KPSS検定 stats, p_value, lags, crit = sm.tsa.kpss(ts, lags=1) print(p_value) #ADF検定 results = sm.tsa.stattools.adfuller(ts, maxlag=1) print(results[0], results[1]) == 0.01 0.5141326404007417 0.9852963752883052
KPSS検定の結果有意水準5%で棄却できるため、1階の差分を取る。
また、以下で対象データの自己相関、偏自己相関を可視化することが可能。
import statsmodels.api as sm fig = plt.figure(figsize=(12, 8)) ax1 = fig.add_subplot(211) fig = sm.graphics.tsa.plot_acf(ts, lags=40, ax=ax1) ax2 = fig.add_subplot(212) fig = sm.graphics.tsa.plot_pacf(ts, lags=40, ax=ax2)

過去のデータの影響が多く残っていることがわかる。
差分を取る
diffで差分系列の生成が可能。
diff_1 = ts.diff(periods=1) #1地点目がNaN(0地点はないため)になるため、dropna() diff_1 = diff_1.dropna()
diff_1に対して、KPSS検定、ADF検定を行う。
from scipy import stats import statsmodels.api as sm #KPSS検定 stats, p_value, lags, crit = sm.tsa.kpss(diff_1, lags=1) print(p_value) #ADF検定 results = sm.tsa.stattools.adfuller(diff_1, maxlag=1) print(results[0], results[1]) == 0.1 -11.507138919509886 4.348218666200526e-21
KPSS検定のp値は0.1で帰無仮説を棄却できない。(=単位根を持つといえない。)
ADF検定のp値は非常に小さく、帰無仮説を棄却できる。(=単位根を持たない)
今回のデータでは、1階差分データでモデリングを進める。
1階差分データと自己相関、偏自己相関のプロットを下に示す。
fig = plt.figure(figsize=(12, 8)) plt.plot(diff_1) import statsmodels.api as sm fig = plt.figure(figsize=(12, 8)) ax1 = fig.add_subplot(211) fig = sm.graphics.tsa.plot_acf(diff_1, lags=40, ax=ax1) ax2 = fig.add_subplot(212) fig = sm.graphics.tsa.plot_pacf(diff_1, lags=40, ax=ax2)


図からは上昇や下降トレンドが除去されていること、7日周期で自己相関が残っていること(=季節性がある)が読み取れる。
そのため、SARIMAモデルで検討を進める。
続いてはモデルの次数を決定していく。
モデルの同定
SARIMAモデルでモデリングするにあたって、グリッドサーチで次数を同定していく。
まずは、最終的な精度確認用に、学習用と検証用でデータを分割する。
検証用データは2週間(7/26~8/8)分とする。
train_term = '2020-07-25' test_term = '2020-07-26' ts_train = ts[:train_term] ts_test = ts[test_term:]
次に、次数の組み合わせのリストを作成し、グリッドサーチを行う。
import itertools #SARIMA(p,d,q)(sp,sd,sq)[s]の次数の範囲を決める。 #範囲は計算量を減らすため、経験上、p,d,qを0~2、sp,sd,sqを0~1くらいに限定する。 p = q = range(0, 3) sp = sd = sq = range(0, 2) #グリッドサーチのために、p,q,sp,sd,sqの組み合わせのリストを作成する。 #定常性の確認よりd=1,周期sは決め打ちで7としている。 pdq = [(x[0], 1, x[1]) for x in list(itertools.product(p, q))] seasonal_pdq = [(x[0], x[1], x[2], 7) for x in list(itertools.product(sp, sd, sq))]
from statsmodels.tsa.statespace.sarimax import SARIMAX import warnings warnings.filterwarnings("ignore") # warningsを表示させない best_result = [0, 0, 10000000] for param in pdq: for param_seasonal in seasonal_pdq: try: mod = SARIMAX(ts_train, order = param, seasonal_order = param_seasonal, enforce_stationarity = True, enforce_invertibility = True) results = mod.fit() print('order{}, s_order{} - AIC: {}'.format(param, param_seasonal, results.aic)) if results.aic < best_result[2]: best_result = [param, param_seasonal, results.aic] except: continue print('AICが最も良いモデル:', best_result)
結果
order(0, 1, 0), s_order(0, 0, 0, 7) - AIC: 2107.264372758358 order(0, 1, 0), s_order(0, 0, 1, 7) - AIC: 2064.6897094263486 order(0, 1, 0), s_order(0, 1, 0, 7) - AIC: 1978.745571580177 order(0, 1, 0), s_order(0, 1, 1, 7) - AIC: 1968.252072625655 order(0, 1, 0), s_order(1, 0, 0, 7) - AIC: 2032.60503887206 order(0, 1, 0), s_order(1, 0, 1, 7) - AIC: 2032.8747358608593 order(0, 1, 0), s_order(1, 1, 0, 7) - AIC: 1966.4668826409086 order(0, 1, 0), s_order(1, 1, 1, 7) - AIC: 1964.4015340247283 order(0, 1, 1), s_order(0, 0, 0, 7) - AIC: 2107.754977372526 order(0, 1, 1), s_order(0, 0, 1, 7) - AIC: 2065.501478375778 order(0, 1, 1), s_order(0, 1, 0, 7) - AIC: 1970.7779191569311 order(0, 1, 1), s_order(0, 1, 1, 7) - AIC: 1966.7078171565583 order(0, 1, 1), s_order(1, 0, 0, 7) - AIC: 2029.7706609442662 order(0, 1, 1), s_order(1, 0, 1, 7) - AIC: 2031.3583794985689 order(0, 1, 1), s_order(1, 1, 0, 7) - AIC: 1965.8745684654855 order(0, 1, 1), s_order(1, 1, 1, 7) - AIC: 1964.2989785834593 order(0, 1, 2), s_order(0, 0, 0, 7) - AIC: 2100.520943117397 order(0, 1, 2), s_order(0, 0, 1, 7) - AIC: 2058.7622249292563 order(0, 1, 2), s_order(0, 1, 0, 7) - AIC: 1968.5875014094959 order(0, 1, 2), s_order(0, 1, 1, 7) - AIC: 1962.6362919760677 order(0, 1, 2), s_order(1, 0, 0, 7) - AIC: 2024.8984699884954 order(0, 1, 2), s_order(1, 0, 1, 7) - AIC: 2026.2700117527102 order(0, 1, 2), s_order(1, 1, 0, 7) - AIC: 1961.4829569904323 order(0, 1, 2), s_order(1, 1, 1, 7) - AIC: 1959.9326195002907 order(1, 1, 0), s_order(0, 0, 0, 7) - AIC: 2108.3420616997973 order(1, 1, 0), s_order(0, 0, 1, 7) - AIC: 2065.9551822598414 order(1, 1, 0), s_order(0, 1, 0, 7) - AIC: 1973.473669971467 order(1, 1, 0), s_order(0, 1, 1, 7) - AIC: 1967.9196222187002 order(1, 1, 0), s_order(1, 0, 0, 7) - AIC: 2031.36552857066 order(1, 1, 0), s_order(1, 0, 1, 7) - AIC: 2032.6046698298364 order(1, 1, 0), s_order(1, 1, 0, 7) - AIC: 1966.8159040096539 order(1, 1, 0), s_order(1, 1, 1, 7) - AIC: 1965.0173038870148 order(1, 1, 1), s_order(0, 0, 0, 7) - AIC: 2108.547740215762 order(1, 1, 1), s_order(0, 0, 1, 7) - AIC: 2060.454795979599 order(1, 1, 1), s_order(0, 1, 0, 7) - AIC: 1968.1782914950297 order(1, 1, 1), s_order(0, 1, 1, 7) - AIC: 1963.348875889112 order(1, 1, 1), s_order(1, 0, 0, 7) - AIC: 2025.1095245679812 order(1, 1, 1), s_order(1, 0, 1, 7) - AIC: 2026.745736538373 order(1, 1, 1), s_order(1, 1, 0, 7) - AIC: 1962.4819894555606 order(1, 1, 1), s_order(1, 1, 1, 7) - AIC: 1960.7625196811855 order(2, 1, 0), s_order(0, 0, 0, 7) - AIC: 2100.6123883855353 order(2, 1, 0), s_order(0, 0, 1, 7) - AIC: 2063.0696896461995 order(2, 1, 0), s_order(0, 1, 0, 7) - AIC: 1972.3855591824868 order(2, 1, 0), s_order(0, 1, 1, 7) - AIC: 1966.122504692755 order(2, 1, 0), s_order(1, 0, 0, 7) - AIC: 2029.7308745018804 order(2, 1, 0), s_order(1, 0, 1, 7) - AIC: 2030.7667337581188 order(2, 1, 0), s_order(1, 1, 0, 7) - AIC: 1964.7360117412372 order(2, 1, 0), s_order(1, 1, 1, 7) - AIC: 1963.0500912538514 order(2, 1, 1), s_order(0, 0, 0, 7) - AIC: 2095.833672222477 order(2, 1, 1), s_order(0, 0, 1, 7) - AIC: 2057.6965130659783 order(2, 1, 1), s_order(0, 1, 0, 7) - AIC: 1969.9264899760578 order(2, 1, 1), s_order(0, 1, 1, 7) - AIC: 1963.3379332111565 order(2, 1, 1), s_order(1, 0, 0, 7) - AIC: 2025.2830018365714 order(2, 1, 1), s_order(1, 0, 1, 7) - AIC: 2026.4239847473932 order(2, 1, 1), s_order(1, 1, 0, 7) - AIC: 1961.9388180754122 order(2, 1, 1), s_order(1, 1, 1, 7) - AIC: 1960.1176123826067 order(2, 1, 2), s_order(0, 0, 0, 7) - AIC: 2061.4179226727774 order(2, 1, 2), s_order(0, 0, 1, 7) - AIC: 2035.6632837286115 order(2, 1, 2), s_order(1, 0, 0, 7) - AIC: 2015.9603720291452 order(2, 1, 2), s_order(1, 0, 1, 7) - AIC: 2015.9558978934915 AICが最も良いモデル: [(0, 1, 2), (1, 1, 1, 7), 1959.9326195002907]
以上の結果から、 ] が導かれた。
パラメータを推定する
モデルの形が特定できたので、次にパラメータの推定を行う。
書くコードとしては、上のグリッドサーチの内部でやっているようにfitを呼ぶだけである。
SARIMA_covid = SARIMAX(endog=ts_train, order=(0,1,2), seasonal_order=(1,1,1,7)).fit() print(SARIMA_covid.summary())
結果
Statespace Model Results ========================================================================================= Dep. Variable: 日本国内 新規罹患者数 No. Observations: 192 Model: SARIMAX(0, 1, 2)x(1, 1, 1, 7) Log Likelihood -974.966 Date: Mon, 10 Aug 2020 AIC 1959.933 Time: 18:33:19 BIC 1976.007 Sample: 01-16-2020 HQIC 1966.448 - 07-25-2020 Covariance Type: opg ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ ma.L1 -0.1578 0.058 -2.711 0.007 -0.272 -0.044 ma.L2 -0.1877 0.051 -3.711 0.000 -0.287 -0.089 ar.S.L7 -0.7121 0.169 -4.206 0.000 -1.044 -0.380 ma.S.L7 0.4902 0.204 2.399 0.016 0.090 0.891 sigma2 2331.5489 185.323 12.581 0.000 1968.323 2694.775 =================================================================================== Ljung-Box (Q): 52.13 Jarque-Bera (JB): 54.54 Prob(Q): 0.09 Prob(JB): 0.00 Heteroskedasticity (H): 16.27 Skew: -0.59 Prob(H) (two-sided): 0.00 Kurtosis: 5.39 =================================================================================== Warnings: [1] Covariance matrix calculated using the outer product of gradients (complex-step).
plot_diagnosticsメソッドで、残差が確認できる。
SARIMA_covid.plot_diagnostics(lags=20, figsize=(16,16));

Q-Qプロットから、残差が正規分布に従っていないように見える。
外生変数を追加することで、モデルの説明力を向上させることができるかもしれないため、SARIMAXでのモデリングも行い、精度を比較してみる。
外生変数として、以下を追加してみる。
- 緊急事態宣言の影響(4/7発令から6日後の4/13 ~ 5/25全国解除の6日後の5/31までを1,それ以外を0)
- 県境をまたぐ移動制限解除の影響(6/19解除から6日後である6/25以前を0,以降を1とするダミー変数)
import numpy as np alert_on = pd.Series(data = 0, index = df[1:]['日付']) alert_on['2020-04-13':] = 1 alert_on['2020-05-31':] = 0 moveRestrict_off = pd.Series(data = 0, index = df[1:]['日付']) moveRestrict_off['2020-06-25':] = 1 sarimax_train = np.stack([alert_on[:train_term].values, moveRestrict_off[:train_term].values],1) sarimax_test = np.stack([alert_on[test_term:].values, moveRestrict_off[test_term:].values],1)
SARIMAXモデルの同定、パラメータ推定の方法は、上で説明したSARIMAとほぼ同じになる。SARIMAXモデルのパラメータとして、exogパラメータを追加することで、SARIMAXモデルとなる。
warnings.filterwarnings("ignore") # warningsを表示させない best_result = [0, 0, 10000000] for param in pdq: for param_seasonal in seasonal_pdq: try: mod = SARIMAX(ts_train, exog = sarimax_train, order = param, seasonal_order = param_seasonal, enforce_stationarity = True, enforce_invertibility = True) results = mod.fit() print('order{}, s_order{} - AIC: {}'.format(param, param_seasonal, results.aic)) if results.aic < best_result[2]: best_result = [param, param_seasonal, results.aic] except: continue print('AICが最も良いモデル:', best_result)
結果
order(0, 1, 0), s_order(0, 0, 0, 7) - AIC: 2105.8852264394372 order(0, 1, 0), s_order(0, 0, 1, 7) - AIC: 2063.516608402309 order(0, 1, 0), s_order(0, 1, 0, 7) - AIC: 1974.922167348323 order(0, 1, 0), s_order(0, 1, 1, 7) - AIC: 1964.0234570834143 order(0, 1, 0), s_order(1, 0, 0, 7) - AIC: 2029.9866441355844 order(0, 1, 0), s_order(1, 0, 1, 7) - AIC: 2029.9502273105097 order(0, 1, 0), s_order(1, 1, 0, 7) - AIC: 1962.4586283326307 order(0, 1, 0), s_order(1, 1, 1, 7) - AIC: 1960.9170337283738 order(0, 1, 1), s_order(0, 0, 0, 7) - AIC: 2106.34779409769 order(0, 1, 1), s_order(0, 0, 1, 7) - AIC: 2063.912796571045 order(0, 1, 1), s_order(0, 1, 0, 7) - AIC: 1967.04571335318 order(0, 1, 1), s_order(0, 1, 1, 7) - AIC: 1962.8026592227798 order(0, 1, 1), s_order(1, 0, 0, 7) - AIC: 2027.13694332749 order(0, 1, 1), s_order(1, 0, 1, 7) - AIC: 2028.6094563954866 order(0, 1, 1), s_order(1, 1, 0, 7) - AIC: 1961.951461076991 order(0, 1, 1), s_order(1, 1, 1, 7) - AIC: 1960.8816558344129 order(0, 1, 2), s_order(0, 0, 0, 7) - AIC: 2100.120865479744 order(0, 1, 2), s_order(0, 0, 1, 7) - AIC: 2057.6283589727036 order(0, 1, 2), s_order(0, 1, 0, 7) - AIC: 1965.1472366928083 order(0, 1, 2), s_order(0, 1, 1, 7) - AIC: 1959.050444293997 order(0, 1, 2), s_order(1, 0, 0, 7) - AIC: 2022.5953619074203 order(0, 1, 2), s_order(1, 0, 1, 7) - AIC: 2024.0191263044044 order(0, 1, 2), s_order(1, 1, 0, 7) - AIC: 1957.9599474261 order(0, 1, 2), s_order(1, 1, 1, 7) - AIC: 1956.792118467596 order(1, 1, 0), s_order(0, 0, 0, 7) - AIC: 2106.9133508037876 order(1, 1, 0), s_order(0, 0, 1, 7) - AIC: 2064.3537752469656 order(1, 1, 0), s_order(0, 1, 0, 7) - AIC: 1969.761032711971 order(1, 1, 0), s_order(0, 1, 1, 7) - AIC: 1963.9555458231923 order(1, 1, 0), s_order(1, 0, 0, 7) - AIC: 2028.7476936829569 order(1, 1, 0), s_order(1, 0, 1, 7) - AIC: 2029.8027076893425 order(1, 1, 0), s_order(1, 1, 0, 7) - AIC: 1962.823624633586 order(1, 1, 0), s_order(1, 1, 1, 7) - AIC: 1961.6219237522719 order(1, 1, 1), s_order(0, 0, 0, 7) - AIC: 2107.8449886846793 order(1, 1, 1), s_order(0, 0, 1, 7) - AIC: 2059.4916308976262 order(1, 1, 1), s_order(0, 1, 0, 7) - AIC: 1965.1149083203754 order(1, 1, 1), s_order(0, 1, 1, 7) - AIC: 1960.1263026585525 order(1, 1, 1), s_order(1, 0, 0, 7) - AIC: 2023.1412659619405 order(1, 1, 1), s_order(1, 0, 1, 7) - AIC: 2024.7071445871811 order(1, 1, 1), s_order(1, 1, 0, 7) - AIC: 1959.2628172347772 order(1, 1, 1), s_order(1, 1, 1, 7) - AIC: 1958.0026296432552 order(1, 1, 2), s_order(0, 1, 0, 7) - AIC: 1967.0735999245207 order(1, 1, 2), s_order(0, 1, 1, 7) - AIC: 1960.690289277761 order(1, 1, 2), s_order(1, 1, 0, 7) - AIC: 1959.5476296503423 order(1, 1, 2), s_order(1, 1, 1, 7) - AIC: 1958.1759097919055 order(2, 1, 0), s_order(0, 0, 0, 7) - AIC: 2100.1802086002217 order(2, 1, 0), s_order(0, 0, 1, 7) - AIC: 2061.562868383704 order(2, 1, 0), s_order(0, 1, 0, 7) - AIC: 1968.4476898969865 order(2, 1, 0), s_order(0, 1, 1, 7) - AIC: 1961.982545761374 order(2, 1, 0), s_order(1, 0, 0, 7) - AIC: 2026.9594531109456 order(2, 1, 0), s_order(1, 0, 1, 7) - AIC: 2028.0350371938757 order(2, 1, 0), s_order(1, 1, 0, 7) - AIC: 1960.7221500782944 order(2, 1, 0), s_order(1, 1, 1, 7) - AIC: 1959.5281067116762 order(2, 1, 1), s_order(0, 0, 0, 7) - AIC: 2096.0242366449816 order(2, 1, 1), s_order(0, 0, 1, 7) - AIC: 2056.917337152522 order(2, 1, 1), s_order(0, 1, 0, 7) - AIC: 1966.7988023910793 order(2, 1, 1), s_order(0, 1, 1, 7) - AIC: 1960.0911407068304 order(2, 1, 1), s_order(1, 0, 0, 7) - AIC: 2023.4714170764519 order(2, 1, 1), s_order(1, 0, 1, 7) - AIC: 2024.55047214786 order(2, 1, 1), s_order(1, 1, 0, 7) - AIC: 1958.8116544529967 order(2, 1, 1), s_order(1, 1, 1, 7) - AIC: 1957.364795327518 order(2, 1, 2), s_order(0, 0, 0, 7) - AIC: 2060.443008126662 order(2, 1, 2), s_order(0, 0, 1, 7) - AIC: 2032.3356492883665 order(2, 1, 2), s_order(0, 1, 0, 7) - AIC: 1966.547204725646 order(2, 1, 2), s_order(0, 1, 1, 7) - AIC: 1951.6710965940904 order(2, 1, 2), s_order(1, 0, 0, 7) - AIC: 2013.1466553406394 order(2, 1, 2), s_order(1, 0, 1, 7) - AIC: 2015.171462294734 order(2, 1, 2), s_order(1, 1, 0, 7) - AIC: 1950.89647489965 order(2, 1, 2), s_order(1, 1, 1, 7) - AIC: 1950.2435103274665 AICが最も良いモデル: [(2, 1, 2), (1, 1, 1, 7), 1950.2435103274665]
SARIMAモデルとは違う次数となった。この次数でモデリングを行う。
SARIMAX_covid = SARIMAX(endog=ts_train, exog=sarimax_train, order=(2,1,2), seasonal_order=(1,1,1,7)).fit() print(SARIMAX_covid.summary())
結果
Statespace Model Results ========================================================================================= Dep. Variable: 日本国内 新規罹患者数 No. Observations: 192 Model: SARIMAX(2, 1, 2)x(1, 1, 1, 7) Log Likelihood -966.122 Date: Mon, 10 Aug 2020 AIC 1950.244 Time: 18:34:28 BIC 1979.178 Sample: 01-16-2020 HQIC 1961.971 - 07-25-2020 Covariance Type: opg ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ x1 -58.4231 19.911 -2.934 0.003 -97.447 -19.399 x2 -59.4909 45.543 -1.306 0.191 -148.754 29.772 ar.L1 1.0240 0.066 15.430 0.000 0.894 1.154 ar.L2 -0.9289 0.070 -13.235 0.000 -1.066 -0.791 ma.L1 -1.0711 0.093 -11.519 0.000 -1.253 -0.889 ma.L2 0.8282 0.093 8.946 0.000 0.647 1.010 ar.S.L7 -0.6705 0.167 -4.006 0.000 -0.998 -0.342 ma.S.L7 0.3804 0.210 1.811 0.070 -0.031 0.792 sigma2 2146.9748 184.244 11.653 0.000 1785.864 2508.086 =================================================================================== Ljung-Box (Q): 41.49 Jarque-Bera (JB): 56.22 Prob(Q): 0.41 Prob(JB): 0.00 Heteroskedasticity (H): 14.24 Skew: -0.72 Prob(H) (two-sided): 0.00 Kurtosis: 5.29 =================================================================================== Warnings: [1] Covariance matrix calculated using the outer product of gradients (complex-step).
x1(緊急事態宣言の影響)は有意となっているが、x2(移動制限の緩和)は有意であるとは言えなかった。
そのためx1のみ採用し、モデリングする。
sarimax_train = np.stack([alert_on[:train_term].values],1) sarimax_test = np.stack([alert_on[test_term:].values],1) SARIMAX_covid = SARIMAX(endog=ts_train, exog=sarimax_train, order=(2,1,2), seasonal_order=(1,1,1,7)).fit() print(SARIMAX_covid.summary())
結果
Statespace Model Results ========================================================================================= Dep. Variable: 日本国内 新規罹患者数 No. Observations: 192 Model: SARIMAX(2, 1, 2)x(1, 1, 1, 7) Log Likelihood -967.710 Date: Mon, 10 Aug 2020 AIC 1951.420 Time: 18:42:55 BIC 1977.139 Sample: 01-16-2020 HQIC 1961.844 - 07-25-2020 Covariance Type: opg ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ x1 -58.5921 19.988 -2.931 0.003 -97.769 -19.416 ar.L1 1.0274 0.073 14.087 0.000 0.884 1.170 ar.L2 -0.9137 0.076 -12.006 0.000 -1.063 -0.765 ma.L1 -1.0725 0.102 -10.469 0.000 -1.273 -0.872 ma.L2 0.8157 0.099 8.216 0.000 0.621 1.010 ar.S.L7 -0.6976 0.159 -4.398 0.000 -1.009 -0.387 ma.S.L7 0.4092 0.201 2.036 0.042 0.015 0.803 sigma2 2164.7336 185.086 11.696 0.000 1801.971 2527.496 =================================================================================== Ljung-Box (Q): 39.69 Jarque-Bera (JB): 48.98 Prob(Q): 0.48 Prob(JB): 0.00 Heteroskedasticity (H): 14.92 Skew: -0.64 Prob(H) (two-sided): 0.00 Kurtosis: 5.18 =================================================================================== Warnings: [1] Covariance matrix calculated using the outer product of gradients (complex-step).
SARIMAX_covid.plot_diagnostics(lags=20, figsize=(16,16));

残念ながらSARIMAXでも残差が正規分布に従っていないように見える。
適切な外生変数の設計は簡単ではない。
推定されたモデルを評価する
作成した2モデルを、検証用データに適用してみる。
pred_sarima = SARIMA_covid.predict(ts.index[0], ts.index[-1]) pred_sarimax = SARIMAX_covid.predict(ts.index[0], ts.index[-1], exog=sarimax_test) plt.figure(figsize=(20,10)) plt.plot(ts, linestyle='-') plt.plot(pred_sarima, "red", linestyle=':') plt.plot(pred_sarimax, "black", linestyle=':')

検証用データのみをプロットした図は以下の通り。
plt.figure(figsize=(20,10)) plt.plot(ts[test_term:], linestyle='-') plt.plot(pred_sarima[test_term:], "red", linestyle=':') plt.plot(pred_sarimax[test_term:], "black", linestyle=':')

データのおおよその傾向をつかめてはいるように見えるものの、数百人単位でズレが出ているところもあり、予測モデルとして使用していくにはさらなる改善が必要である。
予測する
時系列データの場合、作ったモデルで予測するためには過去のデータが必要となる。
そのため、最新のデータを取り込むために、都度モデルを更新して将来予測をしていくことが重要である。
おわりに
思っていたよりかなり長くなってしまいましたが、SARIMA、SARIMAXモデルでの時系列予測をPythonで実装してみました。
疲れた。。。
時系列分析(ARIMAモデルの紹介)
今回は時系列分析について書いてみたいと思います。
気温や株価のように日々変動するデータ(時系列データ)をモデリングする際、時系列モデルが使われます。
時系列モデルでは以下の手法がよく使われています。
- Holt-Winters法(指数平滑化)
- Box-Jenkins法(ARIMA)
- 状態空間モデル
最近、ARIMAモデル(SARIMAXモデルを含む)について勉強をする機会があったので、今回はこちらを紹介したいと思います。
(長くなってしまったので、今回は時系列モデルとは?という部分の紹介、
次回でモデリングについて書いていきます。)
以下の書籍を参考にしています。
時系列分析と状態空間モデルの基礎: RとStanで学ぶ理論と実装
- 作者:真哉, 馬場
- 発売日: 2018/02/14
- メディア: 単行本
Box-Jenkins法とは
時系列分析のフレームワークのようなもの。
以下の手順でモデリングをする。
- データを分析できる形に変換する
- ARIMAなどのモデルを適用し、次数を同定(=モデルの形を特定)する
- パラメータを推定する
- 推定されたモデルを評価する
- 予測する
今回はARIMAモデルについて紹介し、次回、各ステップについて見ていきます。
ARIMAモデルとは
自身の過去のデータを用いて将来予測するモデル。
拡張したものにARIMAX,SARIMA,SARIMAXなどがある。
それぞれ、以下を組み合わせたものである。
- S :季節性(周期性変動)
- 夏はビールが売れる、などの影響を考慮できる
- AR :自己回帰
- 過去t期間のデータから受ける影響を考慮できる。
ARだけのモデルは以下の数式で表される。
- 過去t期間のデータから受ける影響を考慮できる。
- I :和分過程への適用
- 非定常データを分析する際に差分を取る。
- MA :移動平均
- 過去t期間の誤差から受ける影響を考慮できる。
MAだけのモデルは以下の数式で表される。
- 過去t期間の誤差から受ける影響を考慮できる。
- X :外生変数
- 回帰分析のように、変数を取り込める。
定常性
定常性、という言葉が出てきたが、ARIMAモデルは定常データに対して適用することを想定している。
定常性の定義は以下の通り。
期待値が地点tによらず一定であり、共分散も地点によらず、時間差kにのみ依存する、ということを示している。
(k=0の場合は分散となり、地点によらず一定である。)
定常性を持たないデータ(上昇トレンドがあるデータなど)を当てはめる場合は、地点間の差分を取るなどして、定常データにしてから当てはめを行う。
(一階の差分系列で定常にならない場合はさらに差分を取り、二階の差分系列で当てはめを行う。)
モデルの表記
何地点前までのデータを使うか、差分を何回取るかにより、同じARIMAモデルでもモデルの形が異なる。一般的に、添え字p,d,qを用いて以下のように表現する。
ARIMA
pはARの次数、dはIの次数、qはMAの次数を表す。
SARIMAモデルの場合、季節調整のために、さらにP,D,Q,sを追加して、以下のように表現する。
SARIMA
P:P周期前までのデータを参考にする
D:D階差分を取る
Q:Q周期前までの誤差を参考にする
おわりに
今回は、ARIMAモデルとは?という部分を紹介しました。
次回、対象データの定常性を確認し、上に挙げたようなp,d,qなどの次数を特定した後、モデリングを行うところまで確認していきたいと思います。
スケール変換をtrainデータ、testデータ別々に変換してはいけない
まぁ、当たり前といえば当たり前なのですが、、、
オライリーの「Pythonではじめる機械学習」では、標準化などの前処理をする際はテストセットを訓練セットと同じように変換することが重要と書かれています。

Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
- 作者:Andreas C. Muller,Sarah Guido
- 発売日: 2017/05/25
- メディア: 単行本(ソフトカバー)
つまり訓練セットの分散、平均、最大値、最小値などの情報を使ってテストセットも変換する、ということですね。
自分が今まで書いたコードを見てみると、、、やっちゃってました。
今回は、Kaggleの House Prices: Advanced Regression Techniques | Kaggle を題材に、どの程度テストセットへの精度が変わるのか見てみたいと思います。
スケール変換とは?
- 標準化
- 平均0、分散1になるようにデータセットを変換すること。
- Scikit-learnではpreprocessing.StandardScalerクラスが該当する。
- 正規化
- 決まった範囲に収まるようにデータセットを変換すること。
- Scikit-learnではpreprocessing.MinMaxScalerクラスが該当する。
(デフォルトは0.0~1.0) - 最大値、最小値の各データポイントに対する影響が大きく、外れ値に弱い。
その他、Scikit-learnには様々な前処理が用意されている。詳しくは以下を参照ください。
scikit-learn.org
今回はScikit-learnのStandardScalerで前処理を行います。
実際にやってみた
標準化した後にモデルのフィッティングを行い、テストデータに適用します。
(実際には欠損値補完や特徴量の追加を合間にしています。)
コードはこちら
import pandas as pd from sklearn.preprocessing import StandardScaler df = pd.read_csv('./train.csv') /*欠損値補完などの前処理*/ scaler = StandardScaler() scaler.fit(df) X = pd.DataFrame(scaler.transform(df), columns=df.columns) /*モデルのフィッティング*/
フィッティング後、テストデータへ適用する際には以下のようにする。
df_test = pd.read_csv('./test.csv')
/*欠損値補完などの前処理*/
df_test = pd.DataFrame(scaler.transform(df_test), columns=df_test.columns)
この際、再度fitせずにトレーニング時にfitしたscalerを使用する。
(私はここで再度fitしてしまっていた。)
適切な標準化とテストデータにfitさせて標準化したデータを見比べてみよう。

やはり、データのばらつきに違いが生じているようだ。
精度の変化
Ridge回帰、SVR、XGBoostで精度がどのように変化するかを確認する。
- テストデータにfitさせてしまった場合
- Ridge回帰 RmSLE:0.15353
- SVR RmSLE:0.14805
- XGBoost RmSLE:0.14433
- 適切な標準化の場合
- Ridge回帰 RmSLE:0.15325
- SVR RmSLE:0.14798
- XGBoost RmSLE:0.13801
全てのモデルにおいて、RmSLEが小さくなっており、精度が向上した。
特に、XGBoostでの精度の上がり方が目に付く。
言い換えると、適切に標準化を行わないと精度が下がってしまうことを意味する。
おわりに
今回は、精度向上のためにせっかくやった標準化も、やり方を間違えれば精度を落としてしまうことを比較してみました。
今度機会があれば、モデリング部分についても書いてみようかな。